![]() In der ersten Lektion werden Sie erfahren, was HTML ist und wie die Kommunikation im Internet funktioniert. Diese fundamentalen Kenntnisse sind für alle von Bedeutung, die beabsichtigen, eine Webseite zu veröffentlichen. Nachdem Sie alle Lernmodule der ersten Lektion erfolgreich durchgearbeitet haben, werden Sie ein umfassendes Verständnis dafür haben, was HTML-Seiten sind und wie der Austausch von HTML-Seiten zwischen Webbrowser und Webserver erfolgt. Schließlich werden Sie in der Lage sein, eine eigene HTML-Seite zu erstellen, auf der der Text „Hallo Welt“ angezeigt wird.
In der ersten Lektion werden Sie erfahren, was HTML ist und wie die Kommunikation im Internet funktioniert. Diese fundamentalen Kenntnisse sind für alle von Bedeutung, die beabsichtigen, eine Webseite zu veröffentlichen. Nachdem Sie alle Lernmodule der ersten Lektion erfolgreich durchgearbeitet haben, werden Sie ein umfassendes Verständnis dafür haben, was HTML-Seiten sind und wie der Austausch von HTML-Seiten zwischen Webbrowser und Webserver erfolgt. Schließlich werden Sie in der Lage sein, eine eigene HTML-Seite zu erstellen, auf der der Text „Hallo Welt“ angezeigt wird.
Inhalt
| 01.1 | Die Bedeutung von HTML
| 01.2 | Die Historie von HTML
| 01.3 | Die Kommunikation zwischen Webbrowser und Webserver
| 01.3.1 | Die Anfrage des Clients (Request)
| 01.3.1.1 | Die Request-Line
| 01.3.1.2 | Der Anfrage-Header
| 01.3.2 |Die Antwort vom Server (Response)
| 01.3.2.1 | Die Status-Line
| 01.3.2.2 | Der Antwort-Header
| 01.4| Wie Webbrowser Webseiten interpretieren
| 01.4.1 | Parsen und DOM-Baum
| 01.4.2 | Die Darstellung im Browserfenster (Rendern)
| 01.5 | Die Grundstruktur von HTML
| 01.5.1 | Die <html> Tags
| 01.5.2 | Die <head> Tags
| 01.5.3 | Die <body> Tags
| 01.6 | Praktische Übung
| 01.1 | Die Bedeutung von HTML
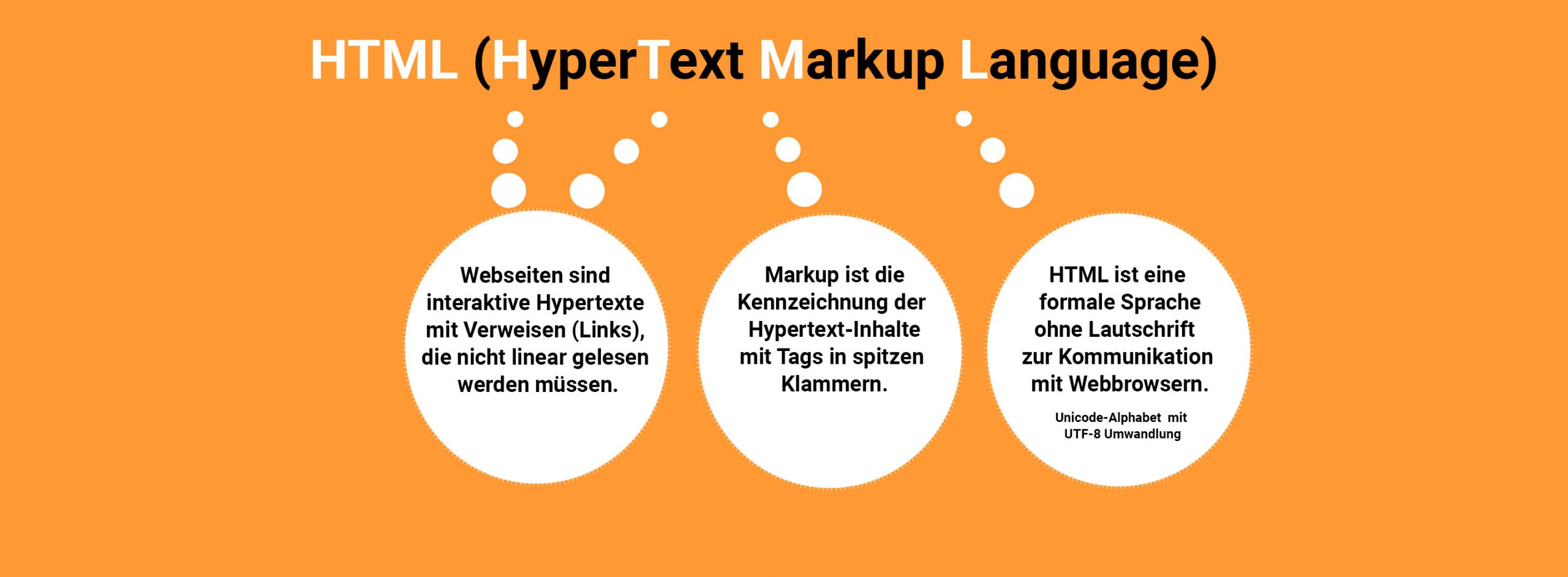
Mit HTML, CSS (Cascading Style Sheets) und JavaScript gibt man Webbrowsern Anweisungen zur Darstellung von Webseiten. Webseiten sind interaktive Hypertexte, bei denen Informationen über Verweise (Links) nicht-linear durchsucht werden können. Im Gegensatz dazu folgt man in einem gedruckten Text auf Papier einer linearen Leserichtung.
Webseiten werden mithilfe der Hypertext Markup Language (HTML) verfasst. In der Informatik werden für die Markierung sogenannte Tags (Etiketten) in spitzen Klammern verwendet. Üblicherweise wird der Inhalt zwischen einem Anfangs- und einem Endtag eingeschlossen, wobei Endtags einen Schrägstrich innerhalb der Klammer aufweisen, wie zum Beispiel <p> Hallo Welt </p>.
HTML ist eine formale Sprache (en: Language) mit festgelegter Syntax und klaren Regeln. Formale Sprachen verfügen zwar nicht über eine gesprochene Aussprache, aber sie verwenden ein bestimmtes Alphabet. Die erlaubten Zeichen für HTML sind Unicode-Zeichen, die für den Computer in Nullen und Einsen übersetzt werden. Dieser Umwandlungsprozess wird als UTF (Unicode Transformation Format) bezeichnet, wobei UTF-8 die am weitesten verbreitete Variante ist. Dabei wird zur Darstellung eines Zeichens 1 Byte (8 Bits) verwendet.
Testen Sie ihr Wissen
01.2 | Die Historie von HTML

Im Jahr 1989 entwickelte Tim Berners-Lee bei der Europäischen Organisation für Kernforschung (CERN) in der Gemeinde Meyrin im Kanton Genf die Hypertext Markup Language (HTML). Seine Absicht war es, Dokumente über Computer miteinander zu verknüpfen, um den Informationsaustausch zwischen den verschiedenen CERN-Instituten zu erleichtern. Zwei Jahre später, 1991, stellte er sein Hypertext-Projekt erstmals vor. Beachtenswerterweise entschied er sich, auf Patente zu verzichten und seine Entwicklung frei zugänglich zu machen. Tim Berners-Lee wird seitdem als der Gründer des World Wide Web (WWW) anerkannt. Heute ist er Professor und Leiter des von ihm ins Leben gerufenen World Wide Web Consortium (W3C), das die HTML-Sprache kontinuierlich weiterentwickelt.
Die erste Version der HTML-Spezifikation wurde im Jahr 1992 veröffentlicht und definierte grundlegende Elemente wie Überschriften, Absätze und Links. Drei Jahre später, im Jahr 1995, erweiterte die Internet Engineering Task Force (IETF) die zweiten Version um Tabellen und Formulare. Die dritte Version , veröffentlicht 1997, führte Hintergrundbilder ein, und zwei Jahre später, in der vierten Version, wurden Cascading Style Sheets (CSS) und Skript-Tags für JavaScript hinzugefügt. Im Jahr 2000 wurde XHTML (Extensible Hypertext Markup Language) eingeführt, eine Kombination aus HTML und XML. Seit 2014 ist die aktuelle Version HTML5 in Verwendung.
Testen Sie ihr Wissen
| 01.3 | Die Kommunikation zwischen Webbrowser und Webserver
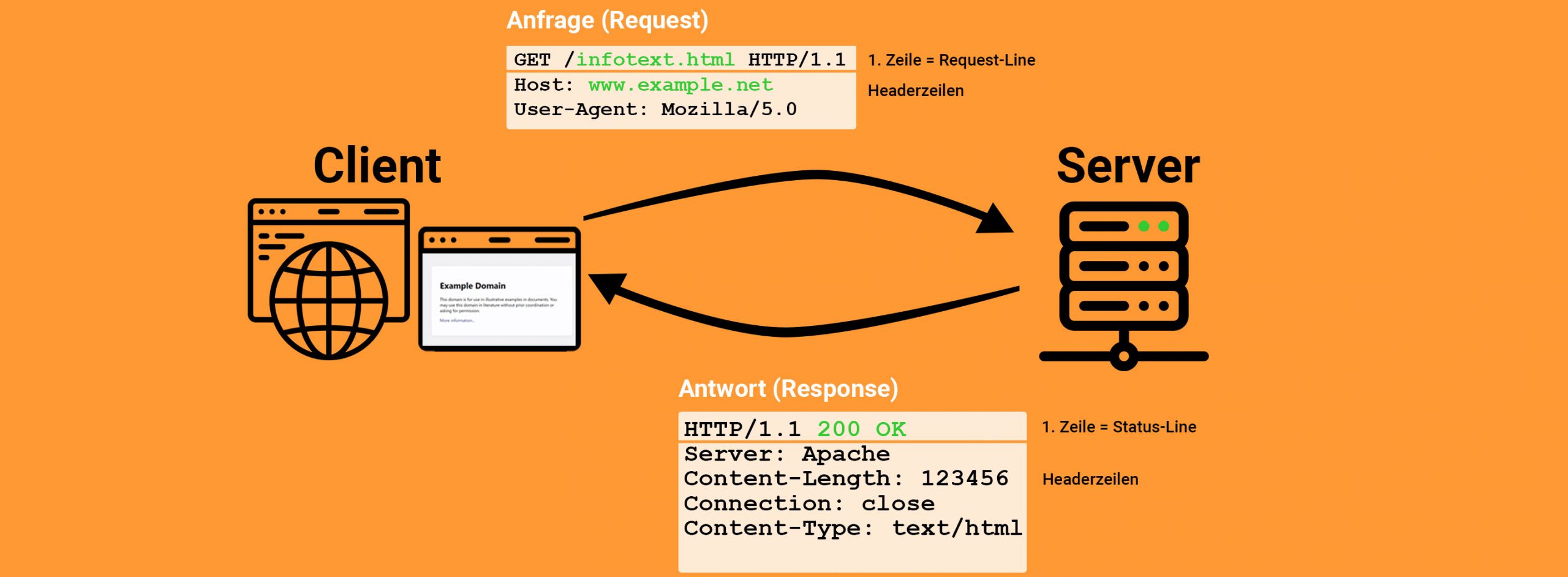

Beim Surfen im Internet interagieren Sie mit einem Webbrowser, einem Computerprogramm (en: Software) zur Darstellung von Webseiten. Sie stellen eine Anfrage an den Browser, ob er eine bestimmte Webseite (URL) anzeigen kann, und dieser leitet Ihre Anfrage an das Gerät weiter, auf dem die Webseite gespeichert (gehostet) ist. Der Webserver antwortet, und Ihr Webbrowser zeigt Ihnen die angeforderte Seite an.
Im Fachjargon wird ein Browser als Client (Kunde oder Auftraggeber) bezeichnet, während das Gerät, an das die Anfrage gerichtet ist, als Server (Diener oder Dienstprogramm) fungiert. Der Client sendet eine Anfrage (Request) an den Server und erhält von diesem eine Antwort (Response). Bei dieser Übertragung werden Datenpakete zwischen den Client- und Serverrechnern hin und her gesendet.
Die genaue Formulierung dieser Nachrichten zwischen Client und Server wird durch das Hypertext-Übertragungsprotokoll HTTP (en: Hypertext Transfer Protocol) geregelt. Dieses Protokoll wurde von der Internet Engineering Task Force (IETF) und dem World Wide Web Consortium (W3C) standardisiert und definiert die Syntax für HTTP-Requests und -Responses.
Die erste offizielle Standard-Protokollversion, HTTP/1.1, wird bis heute verwendet. Mit den neueren Versionen, HTTP/2 und der im Juni 2022 veröffentlichten aktuellen Version HTTP/3, wird angestrebt, die Internetübertragung zu beschleunigen und zu optimieren. Die Nutzung dieser neueren Versionen hängt von Ihrem Hosting-Unternehmen und dem verwendeten Browser ab.
Testen Sie ihr Wissen
| 01.3.1 | Die Anfrage des Clients (Request)
Eine HTTP-Anfrage (Hypertext Transfer Protocol Request) ist ein Datenpaket im Internet, das über ein Netzwerk versendet wird. Programmierer und Administratoren geben ihre Anweisungen (en.: statements) direkt in eine Konsole ein, beispielsweise in die Windows-Eingabeaufforderung. Diese Datagramme bestehen aus mehreren Codezeilen, die in verschiedene Abschnitte unterteilt sind. (Im Gegensatz dazu ist eine Datei eine Sammlung von Daten und kann Texte, Bilder, Videos, Audiodateien oder Programmiercode enthalten.)
| 01.3.1.1 | Die Request-Line

Die Kommunikation zwischen Browser und Server beginnt mit dem ersten Abschnitt einer Anfrage, der sogenannten Anfragezeile (Request Line). Am Anfang der Anfragezeile steht die Anfragemethode (en: Request method). Die am häufigsten verwendete Methode ist GET, mit der ein Client eine Datei vom Server anfordert, um sie anschließend anzuzeigen. Es gibt jedoch auch andere Methoden, die verwendet werden können, um Dateien auf dem Server zu aktualisieren oder zu löschen.
Nach der Angabe der Methode und einem Leerzeichen werden dem Server zunächst die gewünschte Datei und der Dateipfad mitgeteilt. Anschließend folgt erneut ein Leerzeichen, gefolgt von der verwendeten HTTP-Protokoll-Version. Zum Beispiel, wenn Sie die URL http://www.example.net/infotext.html in die Adresszeile Ihres Browsers eingeben, sendet Ihr Browser eine GET-Anfrage an den Rechner mit dem Hostnamen www.example.net, um die Datei infotext.html anzuzeigen.
Testen Sie ihr Wissen
| 01.3.1.2 | Der Anfrage-Header

Im nächsten Abschnitt einer Anfrage folgen die Header-Zeilen, die unterhalb der Anfragezeile stehen. Diese werden auch als Nachrichtenkopf (Message-Header, HTTP-Header) bezeichnet. Die Kopfdaten enthalten sämtliche Informationen, die der Server benötigt, um die Anfrage zu verarbeiten. Eine unverzichtbare Angabe ist der Hostrechner, auf dem sich die angeforderte Datei befindet.
Die Header-Daten sind in der Form von Schlüssel-Wert-Paaren strukturiert, die durch einen Doppelpunkt getrennt sind. Die Schlüssel (en.: key) repräsentieren verschiedene Header-Felder, gefolgt von einem Doppelpunkt und dem zugehörigen Wert (en.: value). Ein Beispiel für ein solches Schlüssel-Wert-Paar ist die Zeile „Host: www.example.net„, bei der nach dem Doppelpunkt des Headerfelds „Host“ der Hostname „www.example.net“ als Wert angegeben wird. Der Hostname, also der Name der URL, wird zunächst mithilfe des DNS-Protokolls in eine IP-Adresse umgewandelt und dann an den Server gesendet.
Die meisten Webbrowser übermitteln standardmäßig auch ihre Browserversion. Hinter dem Doppelpunkt des Headerfelds „User-Agent“ (Clientname) folgt die entsprechende Browserversion (z.B., „Mozilla/5.0“). Darüber hinaus kann dem Server in den Header-Daten mitgeteilt werden, welchen Inhaltstyp (en.: MIME-Typ) der Client verarbeiten kann oder ob ein Nachrichtenrumpf (Message Body, HTTP-Body, Body) mit Nutzdaten (en.: Payload) übertragen wird. Dies ist relevant bei Anfragemethoden, bei denen Texte, Bilder oder Videos auf dem Server aktualisiert werden sollen. Bei einfachen GET-Anfragen ist der Body in der Regel leer.
Testen Sie ihr Wissen
| 01.3.2 | Die Antwort vom Server (Response)
Jede Anfrage wird vom Server beantwortet. Die Antwort setzt sich aus der ersten Zeile, der Status-Line, sowie den Response-Headerzeilen zusammen, in denen Informationen für den Webbrowser übertragen werden.
| 01.3.2.1 |Die Status-Line

In der ersten Zeile, der sogenannten Status-Line, sind die HTTP-Protokollversion und der HTTP-Statuscode enthalten. Bei einer erfolgreichen Bearbeitung der Anfrage sendet der Server den Statuscode „200 OK“ an den Browser (Client) zurück.
Im Falle eines Fehlers wird ein entsprechender Fehlercode übermittelt. Beispiele hierfür sind der Code „404 – Not Found,“ wenn die angeforderte URL nicht gefunden wurde, oder „500 Internal Server Error,“ wenn der Server nicht erreichbar ist. Die Statuscodes sind in fünf verschiedene Kategorien unterteilt:
- Informationscodes (100 bis 199): teilen dem Client mit, dass die Verarbeitung der Anfrage noch andauert
- Erfolgscodes (200 bis 299): bestätigen dem Client eine erfolgreiche Anfrage
- Umleitungscodes (300 bis 399): signalisieren dem Client, dass die Ressource unter einer anderen URL verfügbar ist
- Client-Fehlercodes (400 bis 499): treten auf, wenn die Anfrage aufgrund eines Client-Fehlers fehlschlägt
- Server-Fehlercodes (500 bis 599): treten auf, wenn die Anfrage aufgrund eines Server-Fehlers nicht bearbeitet werden kann
Testen Sie ihr Wissen
| 01.3.2.2 | Der Antwort-Header

Die folgenden Zeilen im Datenpaket gehören zum Nachrichtenkopf (HTTP-Header, Message-Header). Hier finden sich Schlüssel-Wert-Paare mit zusätzlichen Informationen für den Webbrowser.
Nach dem Doppelpunkt im Header-Feld „Server“ wird der Name der Serversoftware angegeben. Die am häufigsten verwendete Webserversoftware im Internet ist Apache. Unter dem Schlüssel „Content-Length“ (de.: Inhaltslänge) wird die Größe der Datei „infotext.html“ in Bytes übermittelt.
Darüber hinaus informiert der Server den Client über den Dateityp (en.: Content-Type), was darauf hinweist, dass eine HTML-Datei übertragen wird. Somit ist klar, dass hier noch ein weiteres Datenpaket, ein Nachrichtenrumpf mit Payload, übermittelt wird.
Testen Sie ihr Wissen
| 01.4 | Wie Webbrowser Webseiten interpretieren

| 01.4.1 | Parsen und DOM-Baum
Nachdem der Browser als Antwort auf seine GET-Anfrage eine HTML-Datei vom Server erhalten hat, beginnt er mit dem Analysieren des HTML-Codes, einem Prozess, der als Parsen bezeichnet wird. Hierbei liest der Browser zunächst die Zeilen der HTML-Datei von oben nach unten und markiert alle Tags sowie deren Inhalte.
Der Browser unterteilt den HTML-Code in kleinere Einheiten, die als Tokens (de: Zeichen) bezeichnet werden (Tokenisierung, en.: Tokenizing). Zum Beispiel würde ein Browser die Codezeile „<p> Hallo Welt </p>“ in drei Tokens aufteilen: „<p>“, „Hallo Welt“ und „</p>“. Die beiden Tags „<p>“ und „</p>“ erkennt er an den eckigen Klammern, während zwischen dem Anfangs- und dem Endtag der Inhalt „Hallo Welt“ steht.
Sobald der Browser den Code gelesen hat, erstellt er eine hierarchische Übersicht aller Tags, die als DOM (Document Object Model)-Baum bezeichnet wird.
Testen Sie ihr Wissen
| 01.4.2 | Die Darstellung im Browserfenster (Rendern)
Nachdem der Browser den DOM-Baum erstellt hat, beginnt er mit dem Rendern, also mit der Darstellung der Webseite im Browserfenster. Zu diesem Zweck liest er zuerst die CSS (Cascading Style Sheets)-Datei ein und anschließend alle anderen Ressourcen, die in der HTML-Datei angegeben sind, wie Bilder, Skripte und Videos. Er ruft diese Ressourcen von den entsprechenden Webservern ab, bindet sie in die Webseite ein und führt angegebene Skripte aus. Sobald die Webseite vollständig angezeigt wird, kann der Benutzer mit ihr interagieren.
Verschiedene Browser interpretieren den HTML-Code unterschiedlich. Daher sollten Webdesigner das Erscheinungsbild der Webseite immer in mehreren Browsern überprüfen. Um sicherzustellen, dass der HTML-Code korrekt dargestellt wird, ist es wichtig, den Code genau zu überprüfen (validieren). Es stehen verschiedene Online-Tools zur Verfügung, um die HTML-Validität zu überprüfen, darunter der Validator des World Wide Web Consortiums (W3C).
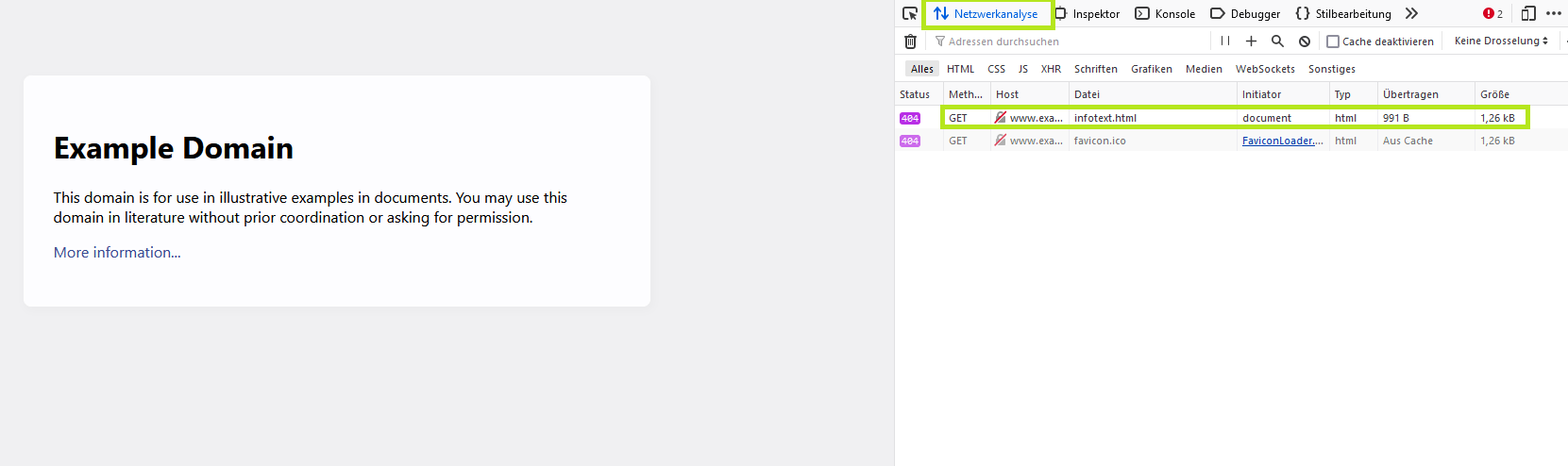
Alle Browser bieten sogenannte Entwicklertools zum Inspizieren und Debuggen von HTML-Seiten. Klicken Sie mit der rechten Maustaste auf eine Webseite und wählen Sie im Kontextmenü die Option „Element untersuchen“ oder „untersuchen“ aus. Die Bezeichnung variiert in Abhängigkeit vom verwendeten Browser. Ein Ansichtsfenster öffnet sich, das sehr viele Informationen über die Webseiten-Struktur enthält, und Sie können sehen, welche Dateien vom Browser angefragt und von den Webservern geliefert werden.
Testen Sie ihr Wissen
| 01.5 | Die Grundstruktur von HTML

HTML-Tags in spitzen Klammern (< >) werden in englischer Sprache verfasst, da das World Wide Web in den Vereinigten Staaten entwickelt wurde und Englisch die vorherrschende Sprache in der Softwareentwicklung ist. Die Elementnamen innerhalb der Tags können bei herkömmlichem HTML sowohl in Groß- als auch in Kleinbuchstaben geschrieben werden, da sie nicht case-sensitiv sind. In XHTML hingegen müssen die Elementnamen in Kleinbuchstaben geschrieben werden, und heutzutage wird generell die Kleinschreibung empfohlen.
Jedes HTML-Dokument beginnt mit dem Tag <!DOCTYPE html>, der den Dokumententyp (DTD) festlegt. Dadurch weiß der Browser, dass es sich um ein HTML-Dokument handelt und welche Syntax er verwenden muss. Das Grundgerüst von HTML-Dokumenten besteht immer aus den Tags <html>, <head> und <body>, die jeweils mit einem Endtag geschlossen werden.
Innerhalb der spitzen Klammern der HTML-Tags können zusätzliche Eigenschaften (Attribute) hinzugefügt werden. Attribute werden immer innerhalb der Tags geschrieben. Hinter dem Tagnamen folgt, durch ein Leerzeichen getrennt, das Attribut, dem mit dem Gleichzeichen ein Wert zugewiesen wird. Auch die Namen der Attribute sind in HTML nicht case-sensitiv. Die Werte der Attribute dürfen sowohl in einfachen als auch in doppelten Anführungszeichen stehen. Es ist ratsam, zu Beginn zu entscheiden, welche Methode Sie für Ihren Code bevorzugen, und konsequent bei Ihrer Wahl zu bleiben.
| 01.5.1 | Die <html> Tags
Die Tags <html> und </html> werden verwendet, um den Anfang und das Ende eines HTML-Dokuments zu markieren. Dadurch weiß der Browser, wo er mit dem Parsen beginnen und wo seine Analyse enden soll. Diese Tags umfassen somit den gesamten Inhalt der Webseite. Im DOM-Baum wird das <html>-Element als Wurzelelement (en.: root element) bezeichnet.
Um die Sprache des Seiteninhalts der Webseite anzugeben, sollte das Sprachenattribut „lang“ (language) im <html>-Tag verwendet werden. Durch die Verwendung des Werts „de“ teilt man dem Browser mit, dass es sich um eine deutsche Seite handelt. Verwendet man den Wert „en“, wird die Seite mit dem Tag <html lang=“en“> als englisch gekennzeichnet. Auf Wikipedia finden Sie eine Übersicht der gültigen Sprachenkürzel.
Testen Sie ihr Wissen
| 01.5.2 | Die <head> Tags
Der <head>-Tag leitet den Kopfbereich ein und wird mit einem </head>-Endtag geschlossen. Die Informationen im Kopfbereich sind für den Browser bestimmt und werden nicht auf der eigentlichen Webseite angezeigt.
Im Kopfbereich finden sich unter anderem Metainformationen, die mit <meta>-Tags eingeführt werden und keine schließenden Tags benötigen. Ein Beispiel ist der Tag <meta charset=“utf-8″>, der dem Browser Informationen über die verwendete Zeichenkodierung, in der Regel utf-8, übermittelt. Mithilfe des Metatags <meta name=“author“ content=“Max Mustermann“> kann der Autor der Webseite angegeben werden.
Eine weitere wichtige Information im Header ist der Webseitentitel, der in den <title></title>-Tags eingefügt wird. Zudem sollte dem Browser mit einem Metatag die Größe des Browserfensters, also der Viewport, mitgeteilt werden, damit er weiß, wie viel Platz für die Anzeige zur Verfügung steht. Die Angabe <meta name=“viewport“ content=“width=device-width, initial-scale=1.0″> ermöglicht es Ihrer Webseite, sich an den Viewport anzupassen und gleichzeitig eine Skalierung zu ermöglichen.
Testen Sie ihr Wissen
| 01.5.3 | Die <body> Tags
Im Nachrichtenrumpf, dem Bereich zwischen dem Starttag <body> und dem Endtag </body>, befinden sich alle Informationen, die im Browserfenster (en: Viewport) angezeigt werden. Dieser Abschnitt enthält die Nutzdaten (en.: Payload), also alles, was auf der Webseite sichtbar ist. In den kommenden Lektionen werden verschiedene HTML-Tags ausführlich erläutert, die die strukturierte Gestaltung von Hypertexten ermöglichen.
Zu den grundlegenden HTML-Tags, die bereits in der ersten HTML-Spezifikation entwickelt wurden, gehören Tags für Verlinkungen sowie Tags zur Textformatierung. Ein Verweis (en.: Link) wird mithilfe der Anker (en.: Anchor)-Tags <a> und </a> erstellt. Überschriften (en: Headline) werden beispielsweise mit <h1></h1> markiert, und für Absätze (en.: paragraphs) werden die <p></p>-Tags verwendet.
Neben den Elementen mit Start- und Endtag gibt es in HTML auch inhaltsleere Elemente, die keinen Endtag benötigen. Diese werden beispielsweise für Zeilenumbrüche (en: line breaks) und Bilder (en: image) verwendet. Mit dem <br>-Tag wird ein Zeilenumbruch eingefügt, und mit dem <img>-Tag wird ein Bild in die Webseite integriert.
Testen Sie ihr Wissen
| 01.6 | Praktische Übung
Schreiben Sie einen HTML-Code, der eine Webseite mit dem Text „Hallo Welt“ anzeigt.
Für Ihre ersten Programmierschritte können Sie HTML Instant verwenden, einen kostenlosen HTML-Editor mit Live-Vorschau. Wenn Sie Ihren Code in das rechte Fenster tippen, können Sie im linken Fenster sehen, wie der Browser die Webseite (also Ihre Programmieranweisungen) darstellt.
HTML-Dokumente sind Textdateien. Daher können Sie am Anfang alternativ auch einen einfachen Text-Editor verwenden, der meist auf jedem Betriebssystem vorinstalliert ist. Beispiele sind der Editor auf Windows-Rechnern oder TextEdit für das Betriebssystem macOS. Wenn Sie mit einem Texteditor arbeiten, müssen Sie die Datei mit ihrem Code (Quelltext) als index.html abspeichern und diese Datei anschließend mit einem Browser öffnen. In der folgenden Demonstration sehen Sie wie man HTML-Quellcode im Windows Editor als index.html abspeichert und die Datei in einem Webbrowser öffnet.
Für professionelles Webdesign empfehle ich Ihnen einen Code-Editor, der die Arbeit sehr vereinfacht, vor allem durch eine farbliche Syntaxhervorhebung. Persönlich verwende ich Visual Studio Code von Microsoft.